Différence entre l'apprentissage automatique supervisé et non surveillé

Différence clé - supervisé contre Sans surveillance Apprentissage automatique
L'apprentissage supervisé et l'apprentissage non surveillé sont deux concepts fondamentaux de l'apprentissage automatique. L'apprentissage supervisé est une tâche d'apprentissage automatique de l'apprentissage d'une fonction qui mappe une entrée à une sortie basée sur l'exemple de paires d'entrée-sortie. L'apprentissage non supervisé est la tâche d'apprentissage automatique de la déduction d'une fonction pour décrire la structure cachée à des données non marquées. Le différence clé entre l'apprentissage automatique supervisé et non surveillé L'apprentissage supervisé utilise des données étiquetées tandis que l'apprentissage non supervisé utilise des données non marquées.
L'apprentissage automatique est un domaine en informatique qui donne à un système informatique la possibilité d'apprendre des données sans être explicitement programmé. Il permet d'analyser les données et de prédire les modèles. Il existe de nombreuses applications de l'apprentissage automatique. Certains d'entre eux sont la reconnaissance du visage, la reconnaissance des gestes et la reconnaissance de la parole. Il existe différents algorithmes liés à l'apprentissage automatique. Certains d'entre eux sont la régression, la classification et le regroupement. Les langages de programmation les plus courants pour le développement d'applications basées sur l'apprentissage automatique sont R et Python. D'autres langues telles que Java, C ++ et Matlab peuvent également être utilisées.
CONTENU
1. Aperçu et différence clé
2. Qu'est-ce que l'apprentissage supervisé
3. Qu'est-ce que l'apprentissage non surveillé
4. Similitudes entre l'apprentissage automatique supervisé et non supervisé
5. Comparaison côte à côte - Apprentissage automatique supervisé vs sous forme tabulaire
6. Résumé
Qu'est-ce que l'apprentissage supervisé?
Dans les systèmes basés sur l'apprentissage automatique, le modèle fonctionne selon un algorithme. Dans l'apprentissage supervisé, le modèle est supervisé. Tout d'abord, il est nécessaire de former le modèle. Avec les connaissances acquises, il peut prédire les réponses pour les futures instances. Le modèle est formé à l'aide d'un ensemble de données étiqueté. Lorsqu'un échantillon de données est donné au système, il peut prédire le résultat. Voici un petit extrait de l'ensemble de données IRIS populaire.
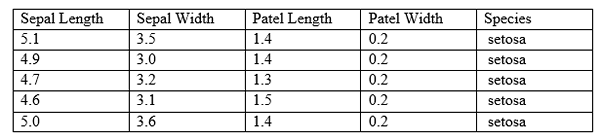
Selon le tableau ci-dessus, la longueur sépale, la largeur sépale, la longueur du ratel, la largeur des rotules et les espèces sont appelées les attributs. Les colonnes sont appelées fonctionnalités. Une ligne a des données pour tous les attributs. Par conséquent, une ligne est appelée observation. Les données peuvent être numériques ou catégoriques. Le modèle reçoit les observations avec le nom de l'espèce correspondante comme entrée. Lorsqu'une nouvelle observation est donnée, le modèle doit prédire le type d'espèce à laquelle il appartient.
Dans l'apprentissage supervisé, il existe des algorithmes pour la classification et la régression. La classification est le processus de classification des données étiquetées. Le modèle a créé des limites qui séparaient les catégories de données. Lorsque de nouvelles données sont fournies au modèle, il peut catégoriser la base de l'endroit où le point existe. Les voisins K-Dearest (KNN) sont un modèle de classification. Selon la valeur k, la catégorie est décidée. Par exemple, lorsque K est 5, si un point de données particulier est proche de huit points de données dans les catégories A et six points de données dans la catégorie B, le point de données sera classé comme un.
La régression est le processus de prédiction de la tendance des données précédentes pour prédire le résultat des nouvelles données. En régression, la sortie peut être composée d'une ou plusieurs variables continues. La prédiction se fait à l'aide d'une ligne qui couvre la plupart des points de données. Le modèle de régression le plus simple est une régression linéaire. Il est rapide et ne nécessite pas de paramètres de réglage tels que dans KNN. Si les données montrent une tendance parabolique, alors le modèle de régression linéaire ne convient pas.
Ce sont quelques exemples d'algorithmes d'apprentissage supervisés. Généralement, les résultats générés par les méthodes d'apprentissage supervisé sont plus précis et fiables car les données d'entrée sont bien connues et étiquetées. Par conséquent, la machine doit analyser uniquement les motifs cachés.
Qu'est-ce que l'apprentissage non surveillé?
Dans l'apprentissage non supervisé, le modèle n'est pas supervisé. Le modèle fonctionne seul, pour prédire les résultats. Il utilise des algorithmes d'apprentissage automatique pour arriver à des conclusions sur des données non marquées. Généralement, les algorithmes d'apprentissage non supervisés sont plus difficiles que les algorithmes d'apprentissage supervisés car il y a peu d'informations. Le clustering est un type d'apprentissage non supervisé. Il peut être utilisé pour regrouper les données inconnues à l'aide d'algorithmes. Le clustering K-Mean et de la densité sont deux algorithmes de clustering.
algorithme K-mean, Place K centroïde au hasard pour chaque cluster. Ensuite, chaque point de données est attribué au centroïde le plus proche. La distance euclidienne est utilisée pour calculer la distance entre le point de données et le centroïde. Les points de données sont classés en groupes. Les positions pour k centroïdes sont à nouveau calculées. La nouvelle position centroïde est déterminée par la moyenne de tous les points du groupe. Encore une fois, chaque point de données est attribué au centroïde le plus proche. Ce processus se répète jusqu'à ce que les centroïdes ne changent plus. K-Mean est un algorithme de clustering rapide, mais il n'y a pas d'initialisation spécifiée des points de clustering. De plus, il existe une grande variation de modèles de clustering basés sur l'initialisation des points de cluster.
Un autre algorithme de clustering est Clustering basé sur la densité. Il est également connu sous le nom d'applications de clustering spatiale basées sur la densité avec du bruit. Il fonctionne en définissant un cluster comme l'ensemble maximum de points connectés de densité. Ce sont deux paramètres utilisés pour le clustering basé sur la densité. Ce sont des points ɛ (epsilon) et minimum. Le ɛ est le rayon maximal du quartier. Les points minimums sont le nombre minimum de points dans le quartier ɛ pour définir un cluster. Ce sont quelques exemples de clustering qui tombe dans l'apprentissage non supervisé.
Généralement, les résultats générés à partir d'algorithmes d'apprentissage non supervisés ne sont pas très précis et fiables car la machine doit définir et étiqueter les données d'entrée avant de déterminer les modèles et fonctions cachés.
Quelle est la similitude entre l'apprentissage automatique supervisé et non supervisé?
- L'apprentissage supervisé et non supervisé sont des types d'apprentissage automatique.
Quelle est la différence entre l'apprentissage automatique supervisé et non supervisé?
Supervisé vs apprentissage automatique non supervisé | |
| L'apprentissage supervisé est la tâche d'apprentissage automatique de l'apprentissage d'une fonction qui mappe une entrée à une sortie basée sur des paires d'exemples d'entrée-sortie. | L'apprentissage non supervisé est la tâche d'apprentissage automatique de la déduction d'une fonction pour décrire la structure cachée à des données non marquées. |
| Fonctionnalité principale | |
| Dans l'apprentissage supervisé, le modèle prédit le résultat basé sur les données d'entrée étiquetées. | Dans un apprentissage non supervisé, le modèle prédit le résultat sans données étiquetées en identifiant les modèles seuls. |
| Précision des résultats | |
| Les résultats générés par les méthodes d'apprentissage supervisé sont plus précis et fiables. | Les résultats générés par les méthodes d'apprentissage non supervisés ne sont pas très précis et fiables. |
| Algorithmes principaux | |
| Il existe des algorithmes de régression et de classification dans l'apprentissage supervisé. | Il existe des algorithmes pour le regroupement dans l'apprentissage non supervisé. |
Résumé - supervisé contre Sans surveillance Apprentissage automatique
L'apprentissage supervisé et l'apprentissage non surveillé sont deux types d'apprentissage automatique. L'apprentissage supervisé est la tâche d'apprentissage automatique de l'apprentissage d'une fonction qui mappe une entrée à une sortie basée sur des paires d'exemples d'entrée-sortie. L'apprentissage non supervisé est la tâche d'apprentissage automatique de la déduction d'une fonction pour décrire la structure cachée à des données non marquées. La différence entre l'apprentissage automatique supervisé et non surveillé est que l'apprentissage supervisé utilise des données étiquetées tandis que le penchoir non supervisé utilise des données non marquées.
Référence:
1.Thebigdatauniversity. Apprentissage automatique - Supervisé vs apprentissage non supervisé, classe cognitive, 13 mars. 2017. Disponible ici
2.«Apprentissage non surveillé.»Wikipedia, Wikimedia Foundation, 20 mars. 2018. Disponible ici
3."Enseignement supervisé.»Wikipedia, Wikimedia Foundation, 15 mars. 2018. Disponible ici
Image gracieuseté:
1.'2729781' par GDJ (domaine public) via Pixabay