Différence entre la similitude et l'identité dans l'alignement de séquence
Le différence clé entre la similitude et l'identité dans l'alignement de séquence est que La similitude est la ressemblance (ressemblance) entre deux séquences en comparaison tandis que l'identité est le nombre de caractères qui correspondent exactement entre deux séquences différentes.
La bioinformatique est un domaine interdisciplinaire de la science qui implique principalement la biologie moléculaire et la génétique, l'informatique, les mathématiques et les statistiques. L'alignement de séquence est un terme majeur en bioinformatique. C'est la procédure dans laquelle les séquences d'ADN, d'ARN ou de protéine sont disposées pour identifier les régions de ressemblance qui sont une conséquence de la relation fonctionnelle, structurelle ou évolutive entre les séquences. À la fin de l'alignement, ils seront présentés sous forme de lignes dans une matrice. Afin d'aligner les caractères identiques dans les coloums successifs, des lacunes insérées sont présentes entre les résidus.
CONTENU
1. Aperçu et différence clé
2. Ce qui est la similitude dans l'alignement de séquence
3. Qu'est-ce que l'identité dans l'alignement de séquence
4. Similitudes entre la similitude et l'identité dans l'alignement de séquence
5. Comparaison côte à côte - similitude vs identité dans l'alignement de séquence sous forme tabulaire
6. Résumé
Qu'est-ce que la similitude?
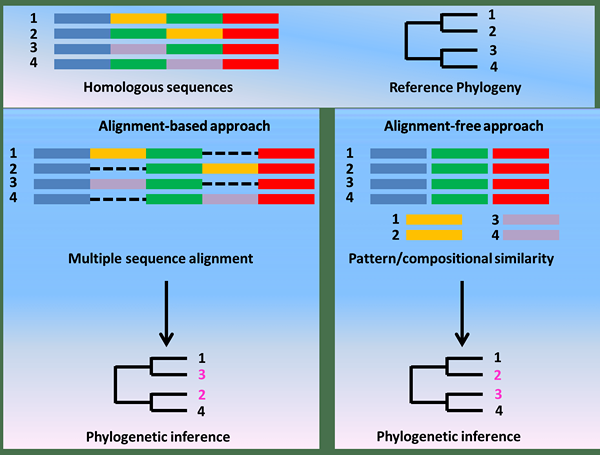
La similitude de l'alignement de séquence est la ressemblance entre deux séquences par rapport. Ce fait dépend de l'identité des séquences. La similitude illustre dans quelle mesure les résidus sont alignés. Par conséquent, des séquences similaires contiennent des propriétés similaires. En bioinformatique, la similitude est un outil pour évaluer la ressemblance entre deux protéines.
Figure 01: similitude dans l'alignement de séquence
Il y a deux étapes principales pour séquencer le processus d'alignement. L'étape initiale est l'alignement par paire, qui aide à trouver l'alignement optimal entre deux séquences (y compris les lacunes) en utilisant des algorithmes tels que Blast, Fasta et Lalign. L'algorithme de correspondance trouve le nombre minimum d'opérations d'édition; dans les dels et les substitutions afin d'aligner une séquence à l'autre séquence. Après l'alignement par paire, il est nécessaire d'obtenir deux paramètres quantitatifs à partir de chaque comparaison par paire. Ils sont l'identité et la similitude.
Qu'est-ce que l'identité?
L'identité de l'alignement de séquence est le nombre de caractères qui correspondent exactement entre deux séquences différentes. Par conséquent, les lacunes ne comptent pas lors de l'évaluation de l'identité. La mesure est considérée comme relationnelle à la séquence plus courte entre les deux séquences. Cela implique de manière significative qu'il a l'effet où l'identité de séquence n'est pas transitive. Si x = y et y = z, alors x n'est pas nécessairement égal à z. Ceci est déduit en termes de mesure de distance d'identité.
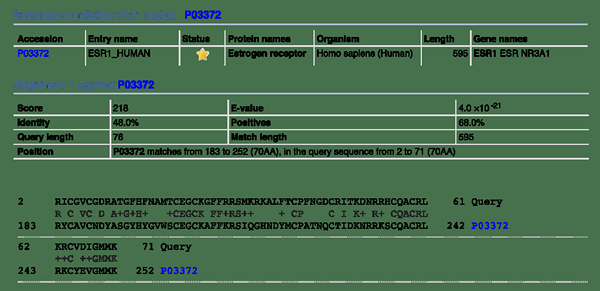
Figure 02: Identité dans l'alignement de séquence
Par exemple, X a une séquence d'Aaggctt, Y a une séquence d'Aaggc et Z a une séquence d'Aaggcat. L'identité entre x et y est 100% 5 nucléotides identiques / min [longueur (x), longueur (y)]. L'identité entre Y et Z est également à 100%. Mais l'identité entre X et Z n'est que de 85% (6 nucléotides identiques / 7).
Quelles sont les similitudes entre la similitude et l'identité dans l'alignement de séquence?
- La similitude et l'identité sont deux termes que nous utilisons dans l'alignement de séquence.
- De plus, ils se réfèrent à la ressemblance entre les deux séquences.
- De plus, nous les exprimons en pourcentage.
Quelle est la différence entre la similitude et l'identité dans l'alignement de séquence?
La similitude d'alignement indique que la ressemblance entre deux séquences par rapport à l'identité dans l'alignement de séquence indique la quantité de caractères qui correspondent exactement entre deux séquences différentes. Par conséquent, c'est la principale différence entre la similitude et l'identité dans l'alignement de séquence.

Résumé - similitude vs identité dans l'alignement de séquence
L'alignement des séquences aide à identifier les régions de ressemblance dans l'ADN, l'ARN ou la protéine abouti à une relation fonctionnelle, structurelle ou évolutive entre les séquences. Par conséquent, la similitude et l'identité sont deux termes clés dans le contexte de l'alignement de séquence. La principale différence entre ces deux termes est que la similitude est la ressemblance entre deux séquences en comparaison tandis que l'identité est le nombre de caractères qui correspondent exactement entre deux séquences différentes. Ainsi, c'est le résumé de la différence entre la similitude et l'identité dans l'alignement de séquence.
Référence:
1. «Identité et similitude - une mesure quantitative.«Identité et similitude - une mesure quantitative, disponible ici.
2. «Alignement de séquence.”Alignement de séquence - Bioinformatique.Org wiki, disponible ici.
Image gracieuseté:
1. «Phylogénie sans alignement et sans alignement» par Kolekar Pandurang - Propre travaux (CC par 3.0) via Commons Wikimedia
2. «Blast Sample Sortie» par FDARDEL - Propre travaux (CC BY-SA 3.0) via Commons Wikimedia