Différence entre le clustering et la classification
Le différence clé entre le clustering et la classification est que Le clustering est une technique d'apprentissage non surveillée qui regroupe des instances similaires sur la base des fonctionnalités tandis que la classification est une technique d'apprentissage supervisée qui attribue des balises prédéfinies aux instances sur la base des fonctionnalités.
Bien que le regroupement et la classification semblent être des processus similaires, il y a une différence entre eux en fonction de leur signification. Dans le monde de l'exploration de données, le regroupement et la classification sont deux types de méthodes d'apprentissage. Ces deux méthodes caractérisent les objets en groupes par une ou plusieurs fonctionnalités.
CONTENU
1. Aperçu et différence clé
2. Qu'est-ce que le regroupement
3. Qu'est-ce que la classification
4. Comparaison côte à côte - clustering vs classification sous forme tabulaire
5. Résumé
Qu'est-ce que le regroupement?
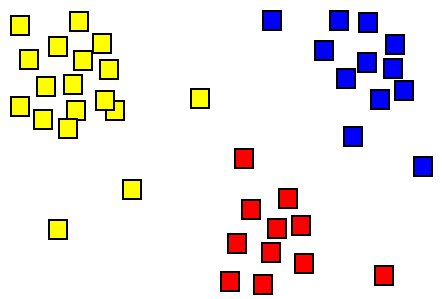
Le clustering est une méthode de regroupement d'objets de telle manière que les objets avec des fonctionnalités similaires se réunissent, et les objets avec des fonctionnalités différentes se séparent. Il s'agit d'une technique courante pour l'analyse des données statistiques pour l'apprentissage automatique et l'exploration de données. L'analyse et la généralisation des données exploratoires sont également un domaine qui utilise le clustering.
Figure 01: regroupement
Le clustering appartient à l'exploration de données non supervisée. Ce n'est pas un algorithme spécifique unique, mais c'est une méthode générale pour résoudre une tâche. Par conséquent, il est possible d'atteindre le regroupement en utilisant divers algorithmes. L'algorithme de cluster et les paramètres appropriés dépendent des ensembles de données individuels. Ce n'est pas une tâche automatique, mais c'est un processus itératif de découverte. Par conséquent, il est nécessaire de modifier le traitement des données et la modélisation des paramètres jusqu'à ce que le résultat atteigne les propriétés souhaitées. Le clustering K-Means et le clustering hiérarchique sont deux algorithmes de clustering communs dans l'exploration de données.
Qu'est-ce que la classification?
La classification est un processus de catégorisation qui utilise un ensemble de données de formation pour reconnaître, différencier et comprendre les objets. La classification est une technique d'apprentissage supervisée où un ensemble de formation et des observations correctement définies sont disponibles.
Figure 02: Classification
L'algorithme qui met en œuvre la classification est le classificateur tandis que les observations sont les instances. L'algorithme du voisin K-Dearest et les algorithmes d'arbre de décision sont les algorithmes de classification les plus célèbres de l'exploration de données.
Quelle est la différence entre le regroupement et la classification?
Le regroupement est un apprentissage non surveillé tandis que la classification est une technique d'apprentissage supervisé. Il regroupe des instances similaires sur la base des fonctionnalités tandis que la classification affecte des balises prédéfinies aux instances sur la base des fonctionnalités. Le clustering divise l'ensemble de données en sous-ensembles pour regrouper les instances avec des fonctionnalités similaires. Il n'utilise pas de données étiquetées ou d'un ensemble de formation. D'un autre côté, catégorisez les nouvelles données en fonction des observations de l'ensemble de formation. L'ensemble de formation est étiqueté.
Le but du regroupement est de regrouper un ensemble d'objets pour savoir s'il existe une relation entre eux, tandis que la classification vise à trouver à quelle classe un nouvel objet appartient à l'ensemble des classes prédéfinies.
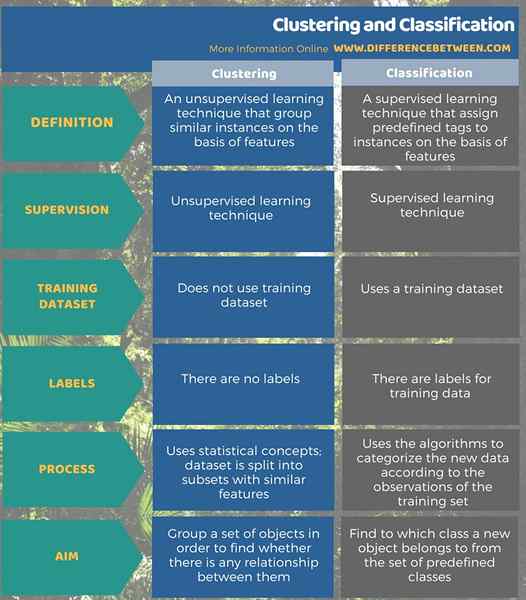
Résumé - Clustering vs Classification
Le clustering et la classification peuvent sembler similaires car les deux algorithmes d'exploration de données divisent l'ensemble de données en sous-ensembles, mais ce sont deux techniques d'apprentissage différentes, dans l'exploration de données pour obtenir des informations fiables à partir d'une collection de données brutes. La différence entre le regroupement et la classification est que le clustering est une technique d'apprentissage non supervisée qui regroupe des instances similaires sur la base des fonctionnalités tandis que la classification est une technique d'apprentissage supervisée qui attribue des étiquettes prédéfinies aux instances sur la base des fonctionnalités.
Image gracieuseté:
1."Cluster-2" par cluster-2.GIF: enfer Travail dérivé: (domaine public) via Wikimedia Commons 2.«Magnétisme» par John Époustouflé - Propre travail. (Domaine public) via Wikimedia Commons